[컴퓨터네트워크] P2P 프로토콜
P2P(Peer to Peer)란?
- 서버 없이 클라이언트(피어)끼리 통신하는 것
- 간헐적으로 연결되어 IP 주소를 교환
- 주로, 파일 배포 및 정보 검색이 이루어진다.
파일의 배포 방식 비교
클라이언트-서버


- N = peer의수, F = File(크기 등) 일 때, N*F = Total로 정의
- Total / (Server의 업로드 Bandwidth) = 서버가 N개의 피어를 향해 F를 업로드하는 시간(Time)
- F / (Peer의 다운로드 Bandwidth) = 피어가 F를 다운로드 받는 시간(Time)
- 즉, 피어의 다운로드 시간은 서버의 환경과 업로드시간이 얼마나 걸리는 진 관계없다.
- 각자의 환경으로 인해, 둘 다 같은 작업을 수행하지만, 서버의 업로드(피어에게 전송하는) 속도와 피어의 다운로드(서버에게 수신받는) 속도가 다를 수 있다. (버퍼에 걸린다는 뜻일걸..?)
- d(cs)는 "서버가 배포를 완료한 시간"이며, 서버의 파일이 모든 클라이언트에 도달한 시간을 의미한다.
- 업로드와 다운로드는 동시에 일어나는 한 가지의 작업이며, 서버의 업로드시간과 가장 늦게 다운로드 받은 피어의 시간을 비교하여 둘 중 가장 오래 걸린 시간을 배포 시간으로 볼 수 있다.
- 참고로 배포시간은 이러한 상황들 중 가장 오래 걸리는 시간을 구하는 것이다.
P2P
- 원본 파일을 여러 개의 청크로 나누어 피어들에게 배포한다.
- 피어들은 인접한 피어와 통신하여 청크를 모으고, 원본파일을 서서히 복구한다.
- 원본파일 짜잔
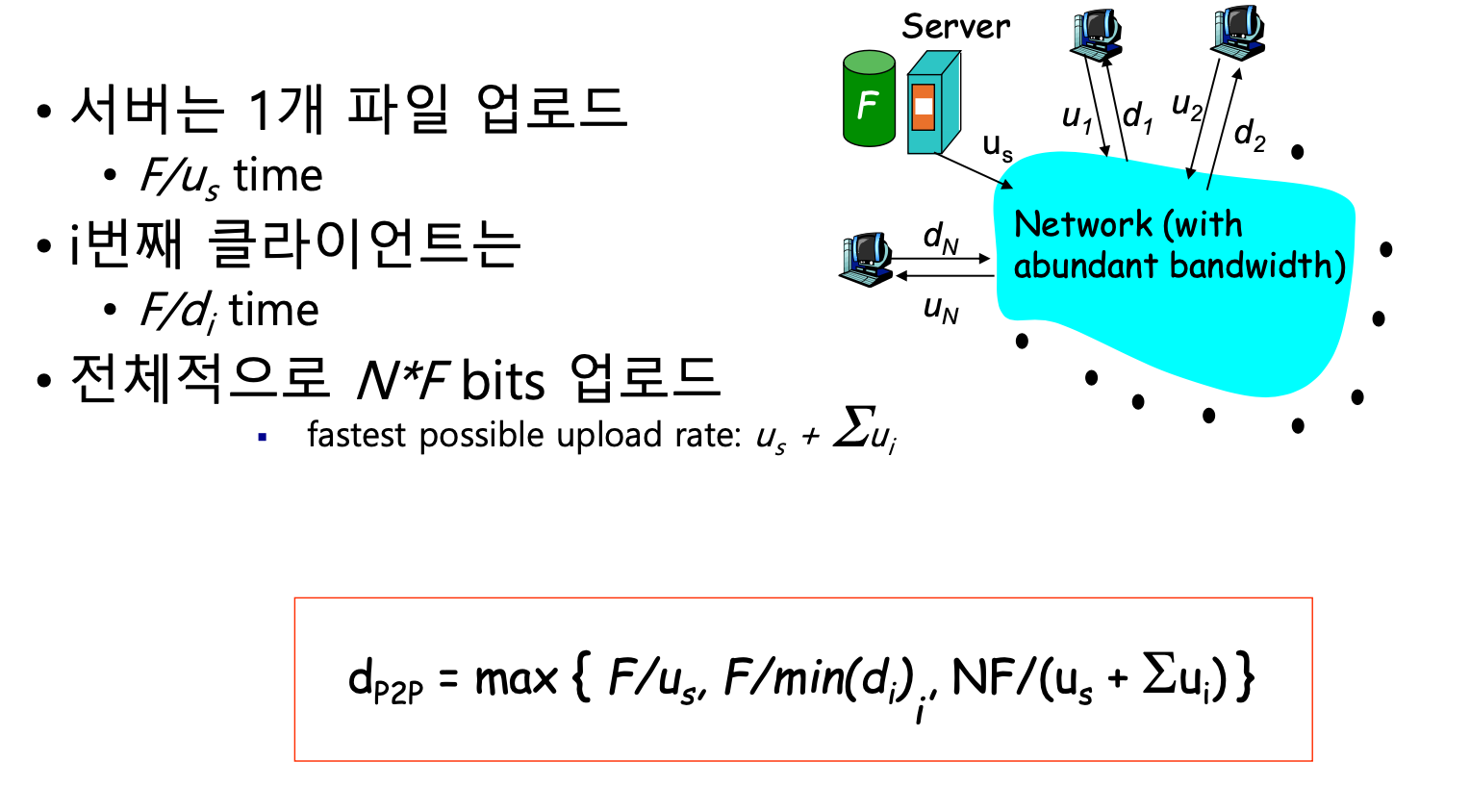
- 1. 원본 파일을 가진 서버가 단 하나의 파일을 1명 이상의 피어들에게 나누어 업로드하는 시간(싱글 쓰레드 기준?)
-> F / (Server의 업로드 Bandwidth)
- 2. Bandwidth의 여건이 가장 나쁜 피어가 모든 청크를 다운로드 받을 때의 시간
- 청크 집합 F = {f1, f2, f3, ... fn} 이고, 피어의 다운로드 bandwidth = d1 일 때
- f1/d1 + f2/d1 + f3/d1 ... fn / d1의 파일 다운로드가 일어난다.
- 결과적으로 ∑fi / d1이 되므로, F/ d1이 된다.
-> F / (Peer의 다운로드 Bandwidth)
- 3. 모든 Peer 및 서버가 자신의 청크를 업로드 하는 시간. 즉, 모든 청크가 업로드 되는 시간
- 왜인지 잘 모르겠지만 fastest possible upload rate는 모든 peer및 서버의 bandwidth 합 us+∑ui이라고 한다.......
- 아무튼 한 peer가 나머지 모든 peer에게 청크를 업로드 하므로, 청크 집합 F = {f1, f2, f3, ... fn} 일 때
- 피어마다 N*f1, N*f2, N*f3 .. N*fn의 파일 업로드가 일어난다. 즉 N*(∑fi , i->n)인데, ∑fi = F이므로, 전체적으로 N*F가 업로드된다.
-> N*F / (us + ∑ui, Server 및 모든 Peer의 업로드 Bandwidth)

- P2P는 N이 증가해도, 한 피어의 다운로드 bandwidth가 비정상적으로 나쁘지 않은 이상, 배포시간은 획기적으로 단축된다.
- 결과적으로 서버의 파일 업로드 부담을 줄였고, 작은 크기의 청크로 인해 한 피어가 부담하는 업로드 Bandwidth또한 줄었다.
- 피어간의 탐색만 빠르게 되면 배포 시간은 클라이언트-서버보다 빠르다.
Bit Torrent 구성 및 용어
- chunk: 한 파일을 구성하는 256KB 단위의 파일
- torrent: 한 파일에 대해 청크를 공유하는 피어의 모임 단위
- tracker: 한 파일에 대해 청크를 가진 피어를 찾는 시스템
Chunk 파일 교환
peer가 torrent에 join
- 해당 피어는 초기에 청크가 없다. 시간이 지남에 따라 다운로드 받게 된다.
- 이후, tracker에게 torrent 구성원 중 자신의 이웃 피어 리스트를 받고 이들과 연결(Connect)된다.
- 이웃 피어 리스트란, 자신으로 부터 인접한 노드를 의미한다. 즉, 모든 피어에 대한 정보를 받진 않는다.
chunks 수신
- 각 피어들은 다른 청크들을 유지한다.
- 주기적으로 피어가 자신의 청크 리스트를 확인하고, 이웃 피어 리스트를 확인하여 청크를 요청한다.
- 청크를 요청 한다는 것은, 이웃의 청크, 피어 리스트도 확인한다는 의미이다.
- 없는 청크 부터 요청한다.
chunk 송신
- 피어가 4개의 이웃에게 청크를 전송한다.
- 매 30초 마다, 다른 이웃 피어를 임의로 선택하여 청크를 전송한다.
Distributed Hash Table(DHT)
- P2P를 위해, 피어가 가진 분산 데이터 베이스, key : value 형식이며, key: chunks(content), value: IP Address
- key가 chunks인 이유는, IP Address를 key로 놓을 경우, 원하는 청크가 나올 때 까지 주소깡을 해야 하기 때문..
- 아무래도.. 원하는 청크를 key로 놓고 찾는게 더 빠르겠죠?
DHT ID
- chunk를 해싱하여, 정수 값을 얻는다.
- 이로써, 각 피어는 고유한 정수 ID 식별자를 가진다.
- ID의 범위는 0 ~ 2^n -1, 즉, n bit 자리수로 표시한다. 이때 n은... 그냥 별도의 사이즈 값이다.
- 이때, 해싱하여 나온 정수값 중, 오차값 +-1인 피어의 ID가 이웃이다.
- 이웃 피어의 ID를 자신의(피어) 데이터 베이스에 key, value (ID, IP Address) 형식으로 할당하여 유지한다.
DHT를 참조하여 청크탐색
선형 탐색

- 자신의 청크리스트를 확인하여 없는 청크를 요청한다.
- 먼저, 이웃에게 해당 청크가 있는지 요청한다.
- 요청을 한다는 것은, 이웃들의 다음 이웃을 확인하여. 재귀적으로 찾아 나간다.
- 마침내 발견할 경우, 해당 키값에 대한 IP Address를 확인하여 서로 연결된다.
- 선형 탐색이 요구되므로, 시간 복잡도는 O(N)이다.
- 요청에 대한 처리는 구체적으로 어떻게되는지 명시가 안되어있다...
더 빠르게 탐색

- 결과적으로, 특정 노드를 추가적으로 듬성듬성 선택하여 이웃을 늘리는 방식이다.
- 이웃이 많으면 뭐... 당연히 시간이 줄어 들겠지요? 선형 탐색은 아니니까.. 막장 같은 알고리즘이라 생각하는데 먹힌다니 뭐..
- 피어가 많을 수록 연결이 매우 복잡 해질 것 같다.